En VítalyTech llevamos tiempo experimentando con herramientas de generación de código asistida a partir de especificacines difusas o incompletas. Un proyecto interno era la ejemplo perfecto para probar la extracción de funcionalidades y generación de especificaciones.
De esta manera, lo que empezó como un prototipo en Lovable acabó siendo una aplicación Angular + FastAPI en producción, con 51 endpoints, 33 componentes, 1.035 tests y un pipeline de generación de 9 fases. Esto es lo que aprendimos.
El punto de partida: un prototipo funcional en Lovable
De forma interna, negocio generó un prototipo completamente navegable en Lovable: 10 pantallas, 9 modales, 3 roles de usuario, flujos de estado complejos.
Era perfecto para validar la UX general y las funcionalidades, pero incompatible con nuestro stack corporativo (Angular + Bootstrap/FastAPI) sobre el arquetipo corporativo frontend y todo ello desplegado en GKE con nuestro CI/CD.
La pregunta era cómo extraer toda esa información y convertirla en especificaciones reales: los nombres de las entidades, las reglas de negocio implícitas en los flujos, los estados de los objetos, los patrones de interacción de cada modal.
La respuesta: convertir el prototipo en fuente de verdad para un agente de análisis, antes de escribir una sola línea de código real.
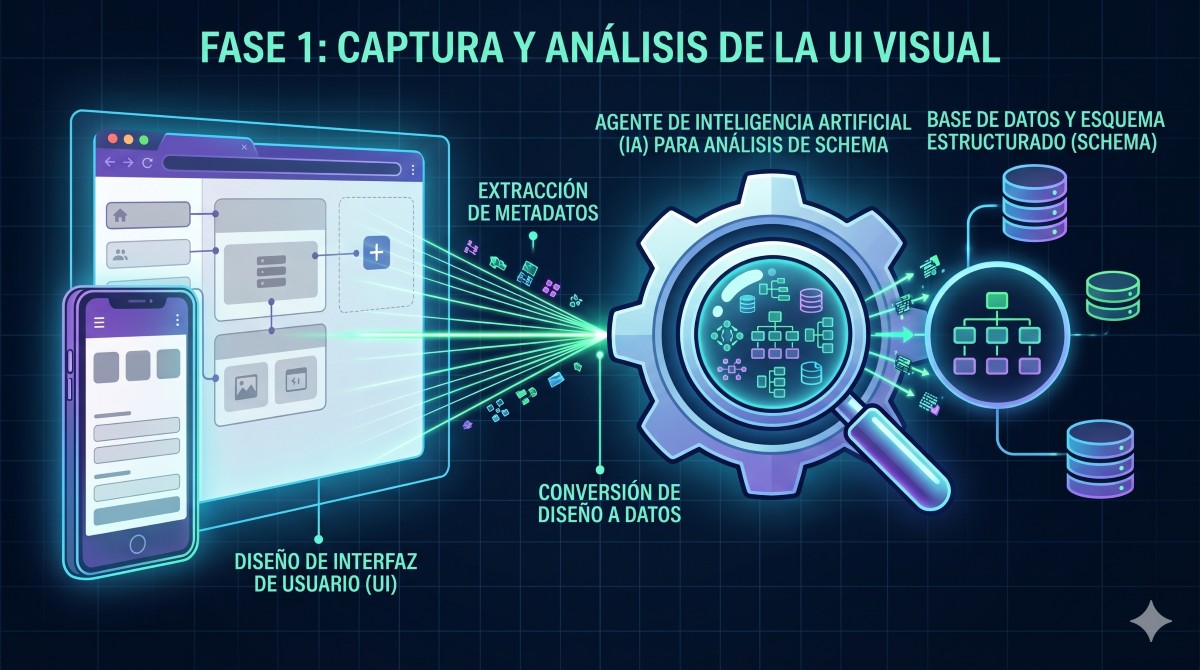
Fase 0: Playwright como escáner de UX
En lugar de documentar el prototipo manualmente, usamos Playwright para navegarlo de forma programática y extraer su contenido. El agente lovable-analyzer capturó:
- 15+ screenshots de cada pantalla y estado
- Inventario de entidades inferidas desde los textos y campos visibles (12 entidades identificadas)
- Árbol de modales por pantalla y rol (M1-M9)
- Flujos de estado de las entidades principales del dominio (7 y 8 estados respectivamente)
Todo esto aterrizó en /lovable-output/ como fuente de verdad para las fases siguientes. La clave fue que el agente no solo «veía» las pantallas: las interpretaba, infería relaciones entre entidades y documentaba las reglas de negocio implícitas en los flujos, apoyándose en la skill lovable-migration, que encapsula el proceso completo de extracción e inventario desde prototipos Lovable.
Fase 1: Arquitectura desde los screenshots
Con las capturas y el inventario en mano, el agente architect generó el plan de implementación completo: estructura de carpetas Angular moderna (standalone, signals, lazy loading), árbol de rutas por rol, estrategia de estado, waves de implementación ordenadas por dependencias, e inventario de los 40+ endpoints necesarios.
El output fue un documento de 1.071 líneas que el equipo revisó, corrigió y aprobó. Esa revisión humana fue el único punto de decisión necesario antes de empezar a generar código.
Algunas decisiones que salieron de esa revisión: standalone bootstrap (eliminar NgModule completamente), DataTable Angular puro sin jQuery, tipos TypeScript generados desde el OpenAPI con openapi-typescript, y guards de auth y rol desde el primer día.
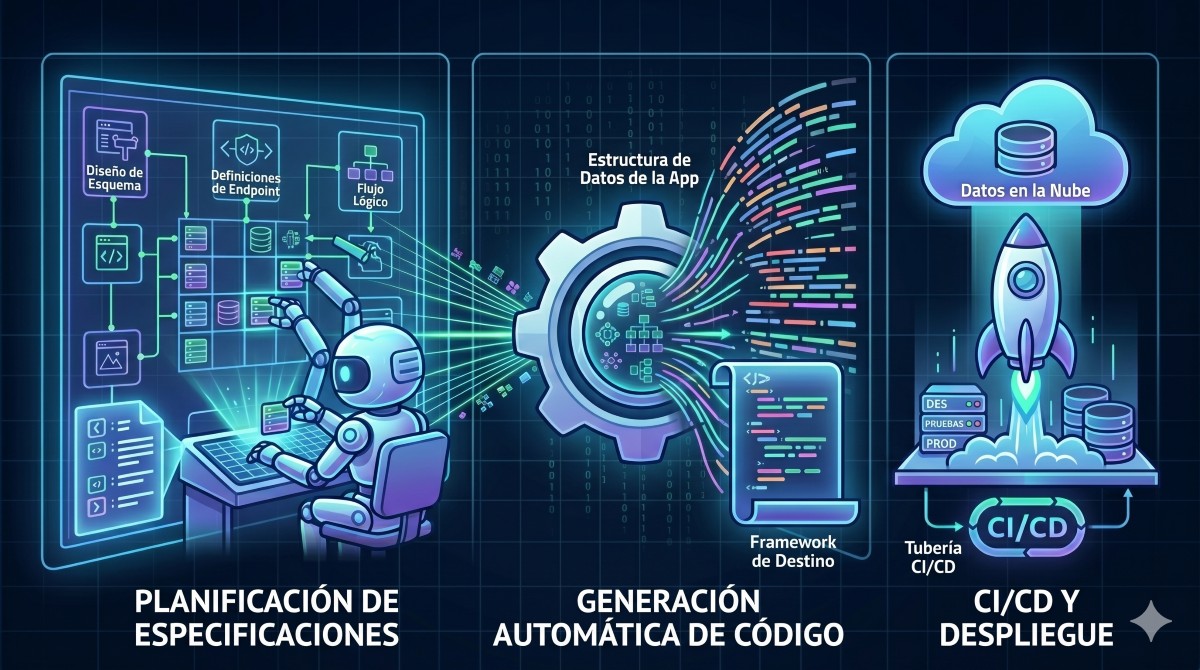
Fase 2: El modelo de datos y el contrato API
Antes de tocar el frontend, dos agentes trabajaron en paralelo: data-modeler definió el modelo de datos (17 tablas, 13 enums, constraints, índices parciales) y api-designer diseñó el contrato OpenAPI (85 schemas, 51 endpoints).
Una particularidad del proyecto: parte de los datos viven en una base de datos corporativa de solo lectura (departamentos, áreas, usuarios,…). El modelo distingue explícitamente entre tablas corporativas (BIGINT IDs, sin FK declaradas) y tablas propias (UUID, soft delete con deleted_at, audit mixins). El agente data-modeler tuvo que navegar esas vistas corporativas para inferir los IDs reales que necesitaría el seed data, guiándose por la skill database-conventions, que codifica exactamente esos patrones propios de la empresa.
Fase 2.5: Frontend-first con mock data
El backend no existía todavía. En lugar de bloquearnos, el agente component-builder construyó el frontend completo con datos mock que seguían exactamente la forma de los tipos OpenAPI. Cada servicio Angular tiene una rama useMocks: true (desarrollo) y una rama HTTP real (producción), controlada por un flag de entorno. El agente se apoyó en las skills angular-patterns y style-guide para mantener coherencia con el arquetipo corporativo desde el primer componente.
Esto nos permitió validar toda la UX con el cliente antes de escribir una línea de backend, generar specs de componentes a partir de los screenshots de Lovable, y detectar divergencias entre el prototipo y la especificación funcional sin esperar al backend.
La generación de specs desde capturas fue especialmente útil en los componentes más complejos: el agente comparaba el screenshot del prototipo Lovable con la implementación Angular —usando también la skill figma-to-angular, adaptada para inferir estructura de componentes desde cualquier referencia visual— e identificaba comportamientos que añadir a los tests.
Fase 3: Backend FastAPI desde el modelo
Con el contrato OpenAPI cerrado, el backend se generó en dos pasos: el agente schema-builder creó toda la infraestructura (Docker, SQLAlchemy async, migraciones Alembic, seed data idempotente) y el agente auth-agent implementó la feature de autenticación con validación del JWT SSO corporativo.
Ambos agentes leyeron la skill backend-patterns al inicio de cada tarea, que define el formato estándar de respuesta API ({ data, error, meta }), el patrón AppError para errores de negocio y la configuración de structlog. La skill database-conventions complementó el trabajo para los aspectos de SQLAlchemy.
El resultado al final de esta fase: alembic upgrade head + python -m app.db.seed + uvicorn y tenías una API funcional con datos de prueba realistas.
Fase 4: Endpoints, tests e integración
El agente endpoint-builder implementó los 51 endpoints feature por feature, siempre leyendo el contrato OpenAPI como fuente de verdad. En paralelo, el agente backend-qa generó los tests de integración (88 tests, 92%+ de cobertura), y el agente integration configuró los Dockerfiles, manifiestos Kubernetes y el pipeline GitLab CI/CD, apoyándose en la skill cicd, que recoge los patrones de despliegue propios de la infraestructura GKE + Istio del proyecto.
La conexión del frontend al backend real reveló las discrepancias habituales: URLs ligeramente distintas, campos en camelCase vs snake_case, estructuras anidadas que el frontend esperaba planas. La solución fue un fichero mappers.ts con ~15 funciones de transformación backend→frontend y un interceptor de auth. El flag useMocks permitió hacer esta integración de forma segura sin romper nada.
El sistema de agentes y skills: la clave de la consistencia
El proyecto tiene 12 agentes y 9 skills, todos versionados en .claude/ dentro del repositorio:
Pipeline de agentes: lovable-analyzer → architect → data-modeler + api-designer → schema-builder + auth-agent → endpoint-builder + component-builder → backend-qa + integration → doc-generator
| Skill | Propósito |
|---|---|
angular-patterns |
Signals, standalone, dual-mode services, guards |
backend-patterns |
AppError, response format, structlog |
cicd |
Docker, K8s GKE + Istio, GitLab pipeline |
database-conventions |
SQLAlchemy, FK corp vs propia, soft delete, audit mixin |
doc-funcional |
Estructura y plantilla del documento funcional |
figma-to-angular |
Inferir componentes desde referencias visuales |
lovable-migration |
Proceso de extracción e inventario desde Lovable |
skill-creator |
Crear y optimizar nuevas skills (meta-skill) |
style-guide |
Tema y paleta corporativa, clases Bootstrap propias, modales, tablas |
La regla de oro del proyecto: cada agente lee su skill antes de actuar, sin excepción. Eso garantiza que el componente número 33 sigue los mismos patrones que el número 1, aunque hayan pasado semanas entre sesiones.
Un gotcha crítico que descubrimos: los subagentes no persisten archivos via MCP filesystem —el write se ejecuta en el contexto del agente pero no llega al sistema de archivos real. La solución fue escribir manualmente en la conversación principal los artefactos generados por los agentes. Nada dramático, pero importante tenerlo en cuenta al diseñar el pipeline.
Fases 6-8: Funcionalidades de negocio y refinamiento visual
Las fases 6A-6F y 7-8 se completaron directamente sin subagentes —el nivel de detalle y el diálogo necesario hacían más eficiente trabajar en la conversación principal:
- Fases 6A-6F: Modales de edición, autoevaluación y evaluación; funcionalidades de rol avanzado (anular entidad, soft-delete, cierre de ciclo, elementos adicionales post-validación); exportación en PDF, DOCX y XLSX; interceptor de errores HTTP; tipado completo eliminando
any; ESLint con 0 errores. - Fase 7 (V1-V11) y Fase 8 (32 mejoras): Paleta soft para status badges, KPI cards con borde corporativo, timeline de revisiones coloreado por tipo, hover de avatares con color cíclico y tooltip, estandarización completa de tamaños y corrección de tildes en ~50 textos.
Cada mejora visual se describía en lenguaje natural en el plan de fase, y el agente la implementaba siguiendo la skill de estilos. La cobertura de tests (1.035, 89% de líneas) fue la red de seguridad que permitió hacer estos cambios con confianza.
El resultado
| Métrica | Valor |
|---|---|
| Endpoints backend | 51 + health |
| Tests backend | 88 (92%+ cobertura) |
| Componentes frontend | 33+, 11 shared |
| Tests frontend | 1.035 (89% líneas) |
| Formatos de exportación | PDF, DOCX, XLSX |
| Roles de usuario | 3 |
| ESLint | 0 errores |
Lo que nos llevamos
Lo que funcionó muy bien: el frontend-first con mocks es la estrategia correcta cuando el backend no existe; los screenshots del prototipo como input para specs ahorraron mucho tiempo de especificación; las skills versionadas en el repo son imprescindibles para mantener consistencia entre sesiones largas; los planes de fase como artefactos Markdown en el repo permiten retomar el trabajo exactamente donde se dejó; y el agente skill-creator para refinar las propias skills fue una inversión que se amortizó rápido.
Lo que aprendimos a hacer mejor: el contrato OpenAPI debe cerrarse antes de generar el backend, no después; las reglas de negocio implícitas en el prototipo hay que hacerlas explícitas en la Fase 0; el agente doc-generator debería invocarse al final de cada fase, no solo al final del proyecto; y las fases con mucho contexto específico son más eficientes sin subagentes.