En la actualidad la mayoría de empresas tienen ya totalmente asumido que es indispensable realizar un análisis de las enormes cantidades de datos que generan diariamente sus sistemas informáticos.
En este sentido, las empresas han ido desarrollando e incorporando a su catálogo de aplicaciones de Inteligencia de Negocio, paneles de mando que facilitan el análisis de los datos de una forma sencilla e interactiva. Y esto permite a las empresas convertir toda esta información en conocimiento y aplicarlo en la toma de decisiones acertadas, en un entorno que es cada vez más competitivo y globalizado.
Sin embargo, en muchas ocasiones estos paneles o cuadros de mando únicamente están accesibles por la Dirección de la empresa que visualiza la información de forma global o, en el mejor de los casos, por los Mandos Intermedios que pueden analizar así los datos asociados a los miembros de sus equipos.
¿Y por qué no damos entonces accesibilidad también a las personas que pertenecen a esos equipos, para que puedan así analizar sus propios datos y tomar ellos también las mejores decisiones? Los motivos pueden ser variados, como haber elegido un software de visualización que obligue a un licenciamiento por usuario y que resulte finalmente demasiado costoso o simplemente que se desconozca cómo crear un cuadro de mando que permita entregar la información de forma personalizada sin perder seguridad.
Pues bien, una vez leas este artículo no tendrás ninguna excusa para no crear un cuadro de mando único, que permita una visualización de la información a nivel de todo un equipo y a nivel individual en función del rol de la persona que acceda al mismo. Un cuadro de mando que democratice tus datos.
 Vamos a usar BigQuery como sistema de almacenamiento de la información y Data Studio como visualizador de los datos y se asume que tienes conocimientos básicos de estas dos herramientas de Google, ya que este artículo no es una guía paso a paso. Si no es el caso y deseas aprender sobre estas dos herramientas, puedes encontrar una gran cantidad de recursos en plataformas de formación on-line, como Udemy o Coursera.
Vamos a usar BigQuery como sistema de almacenamiento de la información y Data Studio como visualizador de los datos y se asume que tienes conocimientos básicos de estas dos herramientas de Google, ya que este artículo no es una guía paso a paso. Si no es el caso y deseas aprender sobre estas dos herramientas, puedes encontrar una gran cantidad de recursos en plataformas de formación on-line, como Udemy o Coursera.
Ejemplo planteado
Para simplificarlo vamos a ver un ejemplo muy sencillo de análisis de las ventas de una red comercial, compuesta por 2 responsables de equipo y 8 comerciales distribuidos entre ellos.
Primero veremos la forma en que obtendríamos un informe de Data Studio destinado a que cada persona responsable de equipo pueda ver sus ventas y las de su equipo, pero no las del otro equipo.
A continuación te mostraré cómo transformar los datos en BigQuery, para que el mismo informe de Data Studio -y esto es lo verdaderamente interesante, no hacer un nuevo informe, si no aprovechar el mismo- sirva para que los miembros de cada equipo también puedan acceder y visualizar sus propias ventas.
Para recoger la información vamos a partir de dos tablas en BigQuery. Por un lado tendremos una tabla con la relación de comerciales y una clave que identifica quién es su jefe de equipo responsable.
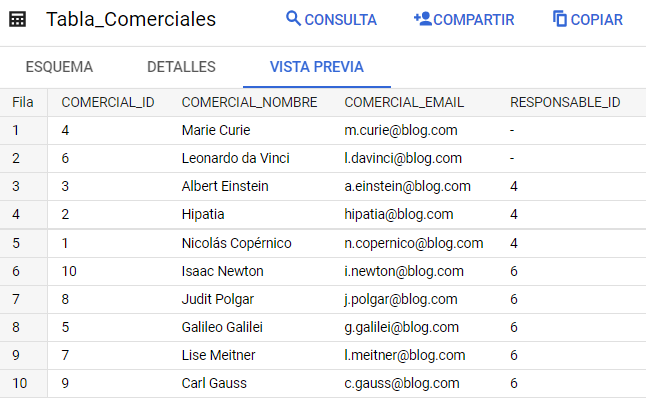
Los 2 comerciales que no tienen ningún responsable, Marie Curie (ID 4) y Leonardo da Vinci (ID 6) serán las personas responsables de equipo comercial, cada uno con 3 y 5 personas a su cargo respectivamente.
Por otro lado tendremos la relación de las ventas realizadas por todos ellos.
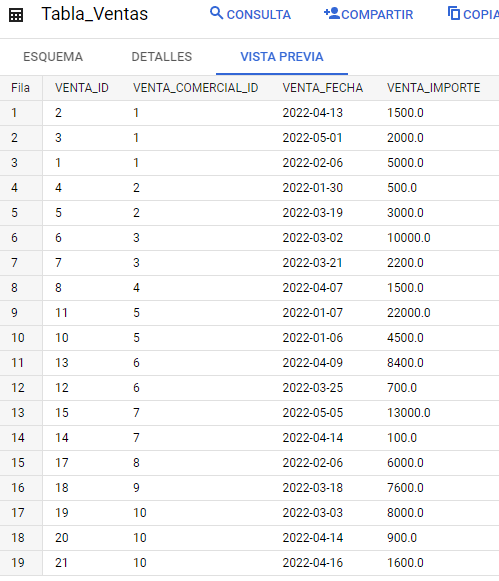
Como ves Marie, y Leonardo también realizan ventas.
Visualización por equipos de venta
Para poder definir los equipos y generar una dirección de correo que luego nos permita filtrar las ventas en el informe de Data Studio y solo muestre los datos del jefe de equipo correspondiente y sus miembros, realizamos una relación muy sencilla:
SELECT
comerciales.COMERCIAL_ID,
comerciales.COMERCIAL_NOMBRE,
comerciales.COMERCIAL_EMAIL,
COALESCE(responsables.COMERCIAL_EMAIL, comerciales.COMERCIAL_EMAIL) AS EMAIL_DATASTUDIO
FROM `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` comerciales
LEFT JOIN `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` responsables ON comerciales.RESPONSABLE_ID = responsables.COMERCIAL_ID
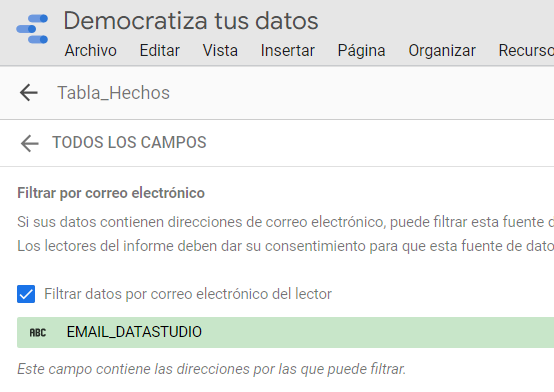
La columna EMAIL_DATASTUDIO contendrá ya la dirección de correo de la persona responsable del equipo. Si combinamos ahora esta consulta con la tabla de ventas obtendremos la tabla de hechos final con 19 registros que utilizaremos como fuente de datos en nuestro informe, filtrando por la dirección de correo. La consulta ampliada sería por tanto así:
WITH equipos AS (
SELECT
comerciales.COMERCIAL_ID,
comerciales.COMERCIAL_NOMBRE,
comerciales.COMERCIAL_EMAIL,
COALESCE(responsables.COMERCIAL_EMAIL, comerciales.COMERCIAL_EMAIL) AS EMAIL_DATASTUDIO
FROM `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` comerciales
LEFT JOIN `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` responsables ON comerciales.RESPONSABLE_ID = responsables.COMERCIAL_ID
)
SELECT
equipos.COMERCIAL_NOMBRE,
ventas.VENTA_FECHA,
ventas.VENTA_IMPORTE,
equipos.EMAIL_DATASTUDIO
FROM equipos
INNER JOIN `preving-blog.BLOG_MODO_DEBUG.Tabla_Ventas` ventas ON equipos.COMERCIAL_ID = ventas.VENTA_COMERCIAL_ID
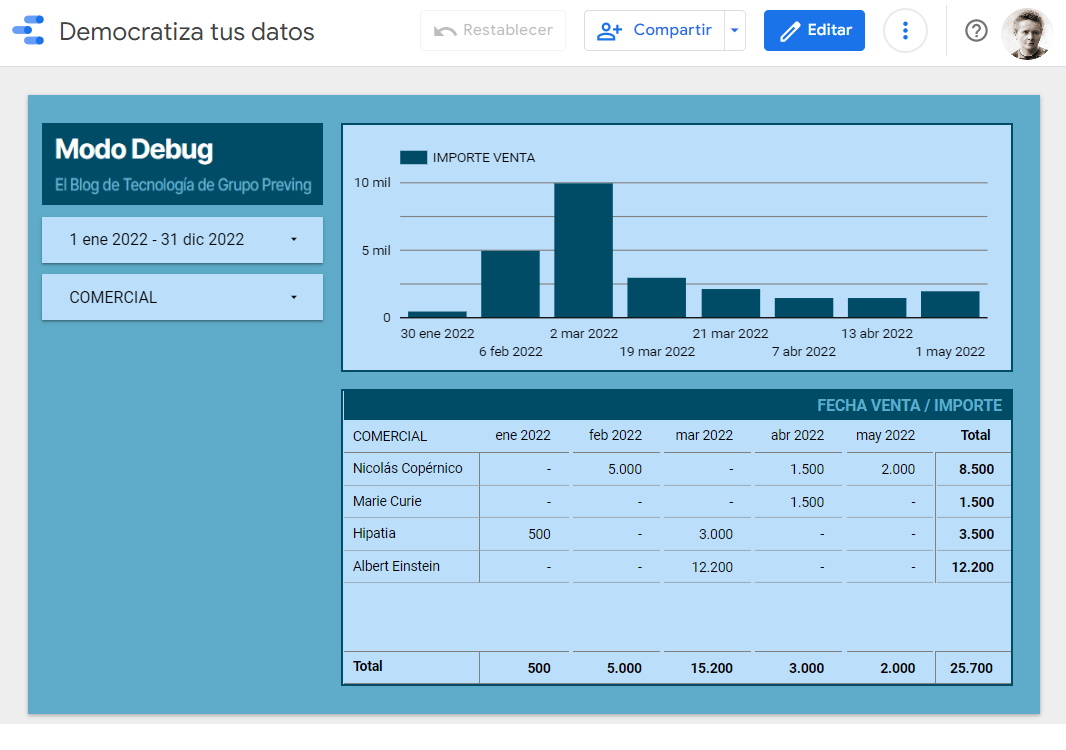
El resultado obtenido permitirá que, al acceder Marie Curie al informe de Data Studio, vea todos los datos de su equipo:
Si accede Leonardo da Vinci, verá lógicamente los datos del suyo:
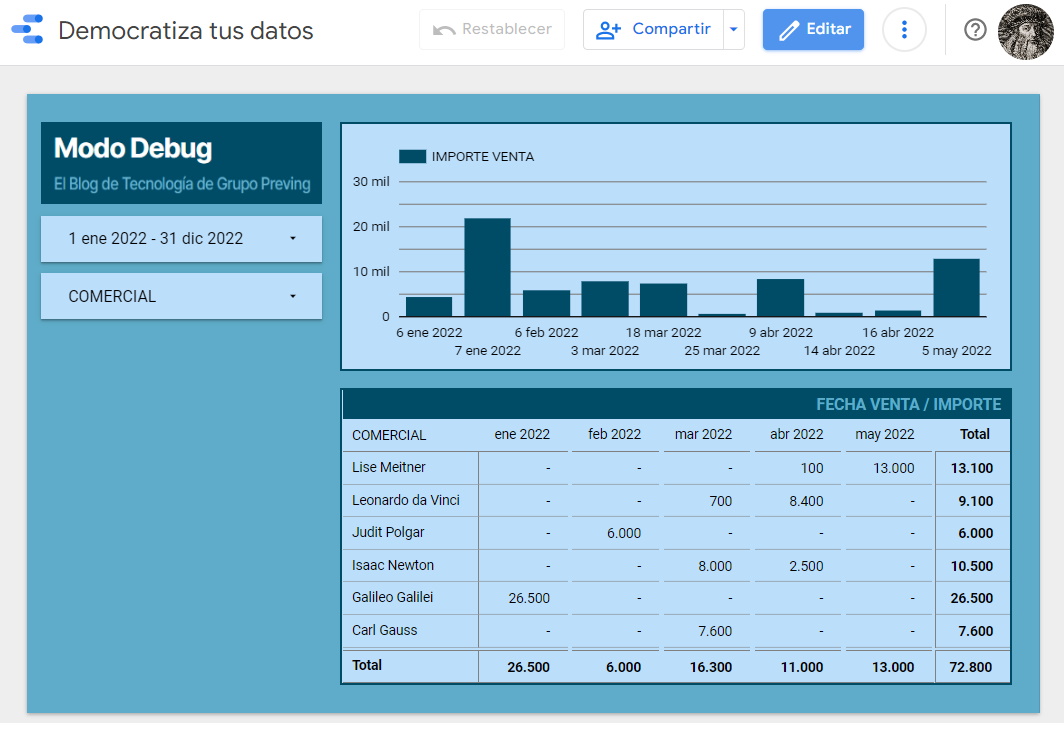
Como hemos comentado, el campo EMAIL_DATASTUDIO es el que utilizamos en la fuente de datos como elemento de seguridad para los lectores del informe:
Democratización de los datos
Ya tenemos una visualización por equipos, pero ahora… ¿cómo conseguimos que cada comercial únicamente vea sus datos al consultar el mismo informe?
Pues muy sencillo, simplemente necesitaremos desdoblar en BigQuery los datos de los comerciales (repetirlos) de tal forma que añadamos de nuevo a todos ellos pero esta vez identificados por su propia dirección de correo en vez de por la dirección de su responsable:
SELECT
comerciales.COMERCIAL_ID,
comerciales.COMERCIAL_NOMBRE,
comerciales.COMERCIAL_EMAIL,
COALESCE(responsables.COMERCIAL_EMAIL, comerciales.COMERCIAL_EMAIL) AS EMAIL_DATASTUDIO
FROM `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` comerciales
LEFT JOIN `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` responsables ON comerciales.RESPONSABLE_ID = responsables.COMERCIAL_ID
UNION DISTINCT
SELECT
comerciales.COMERCIAL_ID,
comerciales.COMERCIAL_NOMBRE,
comerciales.COMERCIAL_EMAIL,
comerciales.COMERCIAL_EMAIL AS EMAIL_DATASTUDIO
FROM `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` comerciales
Si combinamos ahora esta consulta con la tabla de ventas, igual que hicimos anteriormente, obtendremos la tabla de hechos final:
WITH equipos AS (
SELECT
comerciales.COMERCIAL_ID,
comerciales.COMERCIAL_NOMBRE,
comerciales.COMERCIAL_EMAIL,
COALESCE(responsables.COMERCIAL_EMAIL, comerciales.COMERCIAL_EMAIL) AS EMAIL_DATASTUDIO
FROM `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` comerciales
LEFT JOIN `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` responsables ON comerciales.RESPONSABLE_ID = responsables.COMERCIAL_ID
UNION DISTINCT
SELECT
comerciales.COMERCIAL_ID,
comerciales.COMERCIAL_NOMBRE,
comerciales.COMERCIAL_EMAIL,
comerciales.COMERCIAL_EMAIL AS EMAIL_DATASTUDIO
FROM `preving-blog.BLOG_MODO_DEBUG.Tabla_Comerciales` comerciales
)
SELECT
equipos.COMERCIAL_NOMBRE,
ventas.VENTA_FECHA,
ventas.VENTA_IMPORTE,
equipos.EMAIL_DATASTUDIO
FROM equipos
INNER JOIN `preving-blog.BLOG_MODO_DEBUG.Tabla_Ventas` ventas ON equipos.COMERCIAL_ID = ventas.VENTA_COMERCIAL_ID
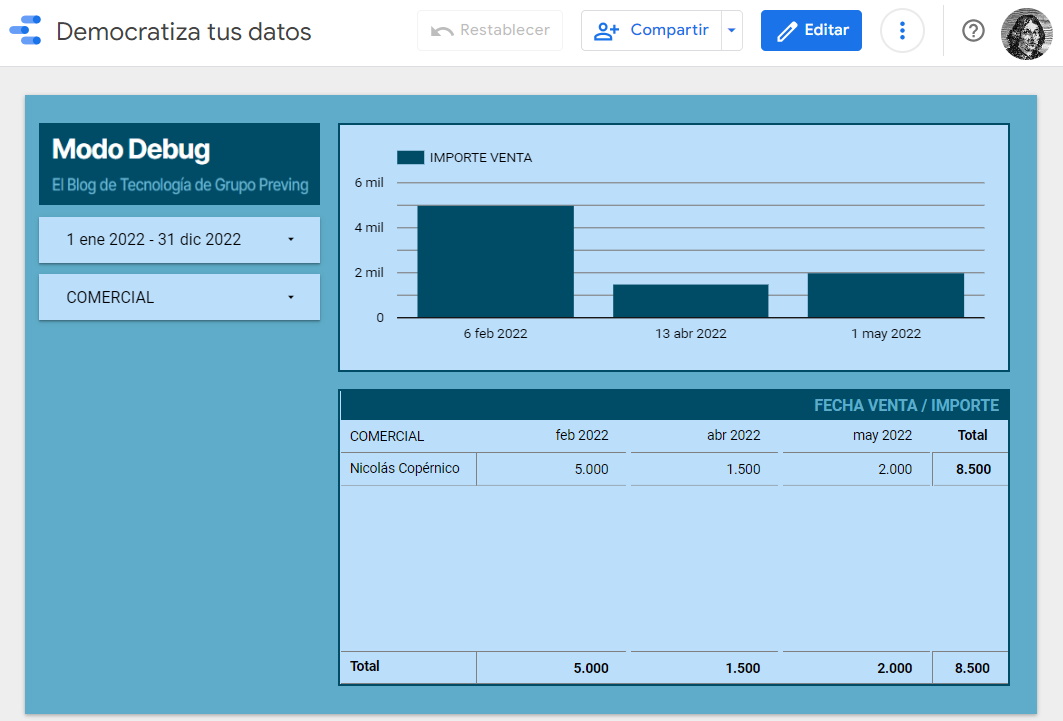
Esta tabla final de ventas contendrá la información identificada por responsables de equipo y por los propios comerciales, pasando de 19 filas de datos a 35. Pero ahora, cualquier comercial que consulte el informe verá exclusivamente sus ventas, como vemos por ejemplo para Nicolás Copérnico:
Conclusiones
Hacer que un mismo cuadro de mando visualice la información a nivel de todo un equipo y a nivel de cada persona individual como ves no requiere ninguna tecnología ni conocimiento especial, únicamente utilizar las herramientas adecuadas y transformar la información.
Ahora bien, ello implica ampliar sensiblemente el volumen de datos a procesar. En nuestro pequeño ejemplo hemos pasado de tener 19 filas en la tabla de hechos a tener 35. Pero si tuviéramos una gran red comercial con cientos de personas y miles de ventas mensuales, o cualquier otro sector de actividad que genere una cantidad de información muy elevada y con muchas personas implicadas, el volumen final de los datos puede llegar a suponer un verdadero problema.
Pero no te preocupes, sigue atento a nuestro blog Modo Debug porque en breve estará disponible una nueva publicación, donde te mostraré cómo encarar esta cuestión y reducir los costes de análisis de Data Studio así como mejorar su rendimiento aplicando otra sencilla técnica.
¡Nos vemos pronto!