¿Qué es Qlik Replicate?
Las empresas actuales tienen múltiples plataformas y bases de datos para respaldar operaciones comerciales, aplicaciones y análisis. Necesitan tener la capacidad de hacer que los datos estén disponibles en cualquier lugar y en cualquier momento; pero mantener la disponibilidad de los datos en entornos heterogéneos puede ser complejo y llevar mucho tiempo y a menudo requiere diferentes herramientas para diferentes fuentes y destinos.
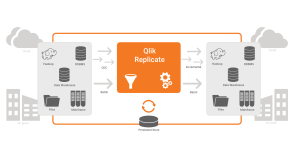
Qlik Replicate (QR) es una plataforma que sirve para replicar, sincronizar, distribuir, consolidar e ingerir datos en todas las principales bases de datos, almacenes de datos y plataformas de Big Data de forma local o en la nube. Permite a las empresas mover sus datos con facilidad, seguridad y eficacia con un impacto muy bajo en las operaciones. Sus características principales serían:
- Captura de Datos Modificados (CDC). Simple, de bajo impacto y basado en registros. QR transfiere los datos en tiempo real de la fuente de datos al destino con la ayuda de una interfaz gráfica (GUI) sencilla, sin necesidad de codificación manual, que automatiza por completo la replicación de un extremo a otro. La CDC basada en registros reduce el impacto en el rendimiento de la replicación en tiempo real. La arquitectura de QR no necesita instalar agentes en los sistemas de bases de datos de origen y está optimizada para la nube.
- Escalable. GUI sencilla que permite acelerar la integración de datos para el análisis: Configurar, ejecutar y monitorear fácilmente todas las tareas de replicación de la empresa a través de un único panel de control, sin codificación manual.
- Gran compatibilidad con fuentes, destinos y plataformas: es compatible con la mayor selección de fuentes y destinos, lo que permite cargar, ingerir, migrar, distribuir, consolidar y sincronizar datos on-premise, entornos cloud o híbridos.
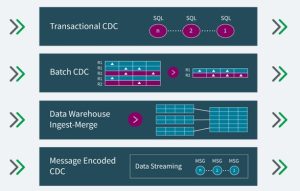
- Plataforma versátil para la CDC. Con la CDC en tiempo real y de bajo impacto para muchos sistemas de bases de datos, QR ofrece opciones flexibles para procesar las CDC:
-
- Transaccional CDC: aplicar las transacciones en el orden en que se comprometieron con la fuente para garantizar una integridad referencial estricta y latencia más baja.
- Batch CDC: Optimizado por lotes: agrupar las transacciones en lotes para optimizar la ingesta de datos y la fusión en almacenes de datos y muchos objetivos en las instalaciones o en la nube.
- Data Warehouse Ingest-Merge: Almacén de datos optimizado: cargar con API nativas optimizadas para el rendimiento para Snowflake, Azure Synapse y otros almacenes de datos que usan procesamiento paralelo masivo (MPP).
- Message Encoded CDC: Transmisión de datos orientada a mensajes: capturar y transmitir registros de cambios de datos en sistemas de agentes de mensajes como Apache Kafka.
- Migración simple y de bajo impacto a la nube: Las empresas están adoptando las ventajas económicas y de flexibilidad de plataformas como Amazon Web Services, Microsoft Azure y Google Cloud Platform. Dichas migraciones, a menudo, pueden retrasarse y aumentar los costes por la complejidad de los desarrollos, los problemas de rendimiento y los riesgos de seguridad. QR simplifica y acelera el proceso de migración de datos desde muchas bases de datos a muchas plataformas en la nube, de manera eficiente y segura, ofreciendo un camino más simple, rápido y seguro para agilizar la migración, gracias a su plataforma GUI sin codificación manual y la tecnología CDC que permite la replicación continua, evitando el tiempo de inactividad y reduciendo el impacto en los sistemas de bases de datos de origen.
Ejemplo práctico
Este ejemplo se basa en la replicación de una base de datos origen tipo MySQL a una de destino tipo PostgreSQL en 5 pasos básicos:
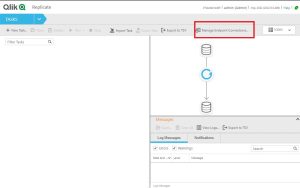
1.Configuración de la Fuentes: Vamos a añadir dos conexiones Endpoint: una Origen y otra de Destino. Clic en ‘Manage Endpoint Connections…’ Seleccionamos en este caso una MySQL como origen y una tipo PostgreSQL como destino, pero podría ser cualquier otro tipo de base de datos soportado por QR.
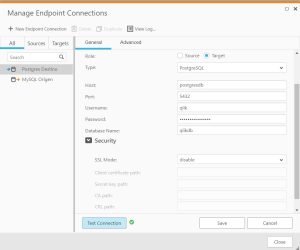
2.Configuración de los 2 Endpoints: Origen y Destino. Introducir los datos de configuración básicos y a continuación hacer un Test de la Conexión y guardar los cambios si la conexión es correcta.
 3.Creación de una nueva Tarea de Replicación. Creamos una tarea de tipo Unidireccional con Carga Completa y Aplicar los cambios activados.
3.Creación de una nueva Tarea de Replicación. Creamos una tarea de tipo Unidireccional con Carga Completa y Aplicar los cambios activados. 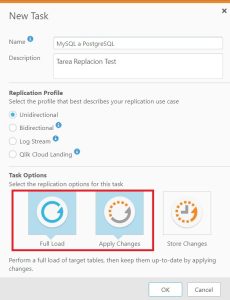
4.Configuración de la Tarea de Replicación. Se necesitan varios puntos para la configuración de la tarea:
-
- Definir punto origen*
- Definir punto destino*
- Selección del esquema y tablas a replicar
- Transformación de datos a realizar: Una vez se han añadido las tablas y se ha creado la tarea, podemos aplicar las transformaciones que creamos oportunas.
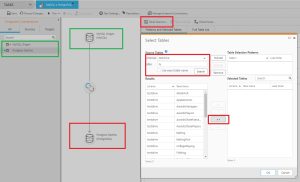
*La interfaz funciona arrastrando los Endpoints listados en la parte izquierda
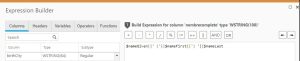
Por ejemplo: Creamos una nueva columna para almacenar el nombre completo resultante de concatenar 3 columnas: nameGiven, NameFirst y nameLast. Modificamos el tamaño del tipo de campo WSTRING (50) a WSTRING (100) y construimos la expresión.
5.Ejecución de la Tarea de Replicación. Iniciamos la tarea con un clic en el comando Run del menú. Al ejecutarse la tarea, pasamos automáticamente al modo Monitor y ahí es donde podemos ver cómo va el proceso de replicación. Hay 4 barras que incluyen las tablas en cada uno de los estados en los que está el proceso de replicación:
- En Cola
- Cargando
- Completado: Si hacemos clic en esta barra vemos las tablas replicadas.
- Error: Existe un fichero de Logs que se puede consultar y en los que se detalla cómo ha ido cada carga y los errores y warnings que ha habido.
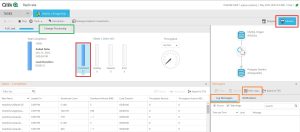
Si seguimos en el modo Monitor, podemos ver el estado del proceso si vamos al menú Change Processing. Ahí también se indica la latencia que hay en la replicación y la última hora de modificación de cada tabla replicada.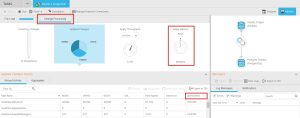
Conclusión
Cómo hemos visto, Qlik Replicate es una herramienta muy útil para las empresas, ya que tiene una gran capacidad de ingesta de datos a través de diversas fuentes de datos. Nos permite que los datos de la empresa estén disponibles en cualquier lugar y en cualquier momento, manteniendo su disponibilidad desde entornos heterogéneos de manera sencilla gracias a un entorno gráfico que nos permite realizar cualquier tarea de replicación y monitorizarla sin necesidad de codificación manual.
Os invito a que veáis lo sencilla y a la vez potente que es esta herramienta. En la propia página web de Qlik y después de registrarnos, podemos acceder por unas horas a una Demo gratuita.