Evolución hacia una Plataforma de Agentes Inteligentes
La implementación de Inteligencia Artificial en nuestro entorno corporativo ha superado su primera etapa. Lo que comenzó con sistemas de RAG (Generación Aumentada por Recuperación) plenamente operativos sobre infraestructuras como Azure Kubernetes, ha empezado a tocar techo frente a las nuevas demandas de autonomía, razonamiento y velocidad.
Mantener bases de datos vectoriales aisladas y «scripts de pegamento» para unir piezas, aunque funcional en producción, genera fricción operativa y limita la capacidad de escalar. Por ello, hemos realizado una reingeniería completa hacia un Stack Agéntico Nativo.
Este artículo detalla nuestra migración estratégica hacia una arquitectura unificada que combina la memoria de MongoDB Atlas, la orquestación de Google ADK y la gobernanza de LiteLLM sobre Google Kubernetes Engine (GKE).
1. La Capa de Datos: Unificación de Cargas de Trabajo Operativas y Vectoriales
1.1 El Paradigma Inicial
En nuestra primera fase de adopción de la IA Generativa, optamos por lo que entonces era el estándar de la industria: integrar bases de datos vectoriales especializadas (Pinecone) para gestionar el almacenamiento de incrustaciones (embeddings) y la búsqueda de similitud.
Esta decisión configuró nuestra arquitectura bajo un modelo de «persistencia políglota». Mientras nuestros datos transaccionales y de negocio residían en su sistema central (MongoDB), los vectores semánticos vivían en un sistema separado y aislado.
Si bien estos almacenes especializados nos ofrecieron un alto rendimiento inicial en la búsqueda de similitud, esta separación estructural nos obligó a pagar un alto precio operativo, conocido como el «impuesto de sincronización».
La Latencia en la Consistencia de Datos
El problema más crítico en una arquitectura desacoplada es la latencia de consistencia. Cuando un documento se actualiza en el registro transaccional, la incrustación vectorial correspondiente debe ser recalculada y actualizada («upsert») en la base de datos vectorial. Cualquier retraso en esta canalización conduce a «alucinaciones», donde la IA recupera información obsoleta que ya no refleja la realidad del negocio.
Complejidad en el Filtrado de Metadatos
Realizar consultas que combinen similitud semántica (búsqueda vectorial) con filtros de metadatos estrictos requiere una indexación eficiente a través de campos vectoriales y escalares. En sistemas separados, esto a menudo implica uniones ineficientes en el lado de la aplicación o un pre-filtrado que degrada la recuperación.
Sobrecarga Operativa y de Seguridad
Gestionar dos infraestructuras de bases de datos distintas duplica la carga sobre los equipos . Además, aumenta la superficie de ataque; cada base de datos adicional es un nuevo punto final que debe ser asegurado, monitoreado y auditado.
1.2 MongoDB Atlas Vector Search: El Enfoque Unificado
La migración a MongoDB Atlas Vector Search aborda estos problemas de fragmentación al incrustar capacidades de almacenamiento y recuperación vectorial directamente en la base de datos de documentos. Esta convergencia no es simplemente una conveniencia; representa un cambio hacia aplicaciones «Vector-Nativas» donde la comprensión semántica es un ciudadano de primera clase del modelo de datos.
Arquitectura y Rendimiento a Escala
MongoDB Atlas utiliza un motor de búsqueda dedicado basado en Lucene (Atlas Search) integrado con la base de datos central. Las incrustaciones vectoriales se almacenan como matrices de números de punto flotante directamente dentro de los documentos JSON, lo que permite una cohesión de datos sin precedentes.
La estrategia de indexación de Atlas Vector Search soporta el algoritmo de Vecino Más Cercano Aproximado (ANN) a través de gráficos HNSW. Esto permite una recuperación de latencia ultra baja incluso a través de millones de vectores. Crucialmente, el índice se sincroniza automáticamente con los datos de la colección. Cuando se inserta o actualiza un documento, el índice vectorial se actualiza casi en tiempo real a través del oplog de MongoDB, eliminando el retraso de sincronización inherente a las arquitecturas desacopladas.
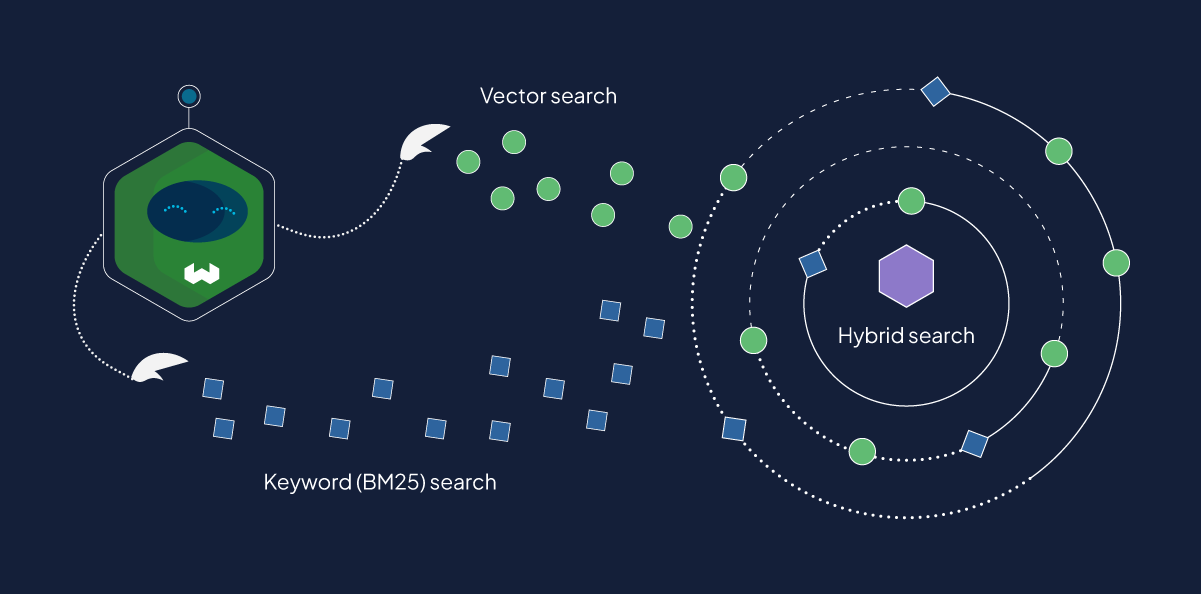
Búsqueda Híbrida y Filtrado Avanzado
Una de las ventajas más profundas de esta migración es la capacidad de realizar un pre-filtrado dentro de la operación de búsqueda vectorial utilizando la etapa de agregación $vectorSearch
Además, esta arquitectura soporta la Búsqueda Híbrida, que combina la precisión de la búsqueda basada en palabras clave (BM25) con la amplitud semántica de la búsqueda vectorial.
El mecanismo subyacente es sofisticado: una consulta se procesa dos veces, una para coincidencias exactas de palabras clave (manejando nombres de productos específicos o ID que los modelos semánticos podrían pasar por alto) y otra para el significado semántico. Los resultados se fusionan utilizando Reciprocal Rank Fusion (RRF), un algoritmo de clasificación que normaliza las puntuaciones de ambos métodos para producir un conjunto de resultados final que es robusto frente a las debilidades de cualquiera de los enfoques individuales.
La búsqueda híbrida captura tanto el token exacto como el contexto semántico, proporcionando una relevancia superior.
2. La Capa de Inteligencia: Flujos de Trabajo Agénticos
2.1 De RAG Lineal a RAG Agéntico
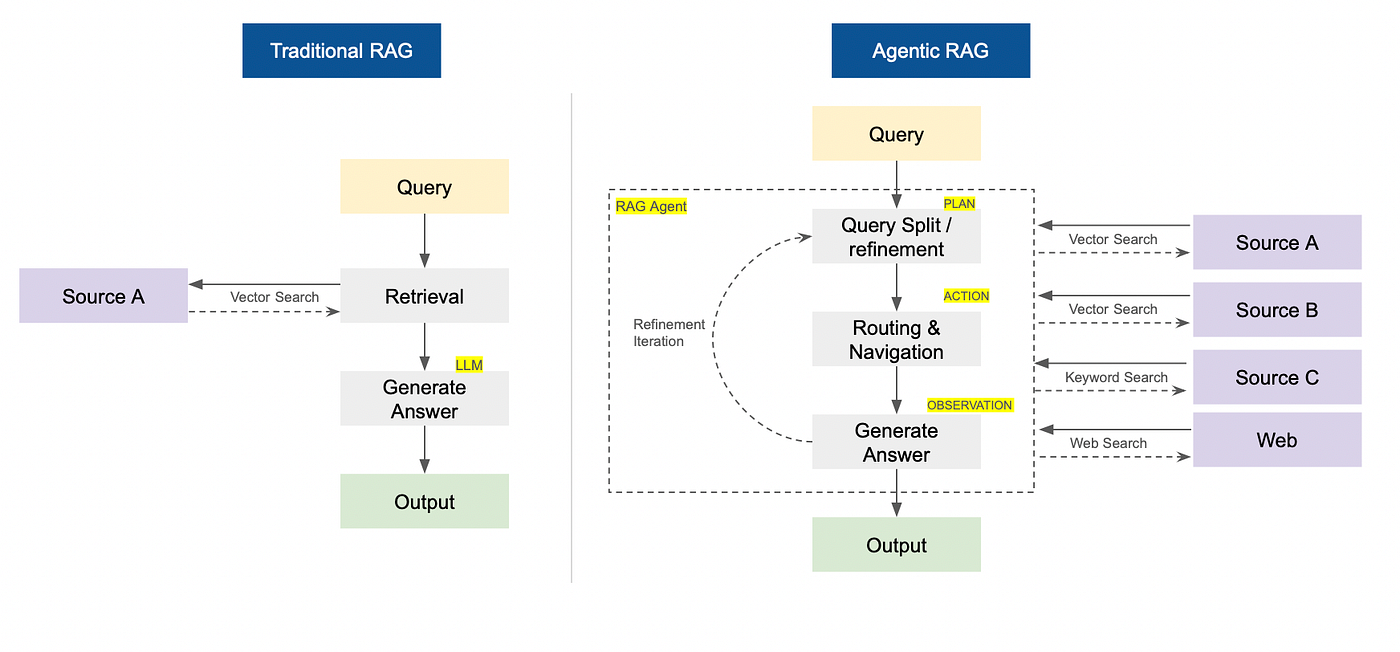
Los sistemas RAG estándar siguen una tubería lineal de «Recuperar-Luego-Generar»: el usuario hace una pregunta, el sistema recupera fragmentos relevantes y el LLM sintetiza una respuesta. Esto funciona bien para consultas estáticas, pero falla cuando el problema requiere razonamiento de múltiples pasos, uso de herramientas o aclaración de ambigüedades.
La migración a una arquitectura de RAG Agéntico introduce un bucle de control dinámico. En lugar de un solo paso, un agente de IA opera en un bucle de Planificación → Búsqueda→ Síntesis.
En la fase de Planificación, el agente analiza la solicitud del usuario y la descompone en subtareas.
En la fase de Actuación, el agente utiliza «herramientas» y fuentes de datos asociadas para realizar búsquedas en paralelo.
En la fase de Síntesis, el agente evalúa la salida de las fuentes y herramientas. Si los datos recuperados son insuficientes o ambiguos, modifica su plan y prueba una estrategia diferente, en lugar de alucinar una respuesta.
2.2 Google Agent Development Kit (ADK): El Marco de Orquestación
El marco de orquestación central seleccionado para esta migración es el Agent Development Kit (ADK) de Google. Si bien el panorama de la IA generativa está abarrotado de marcos, ADK ofrece ventajas específicas para el despliegue empresarial, particularmente dentro del ecosistema de Google Cloud.
Integración Profunda con Vertex AI y Gemini
ADK está diseñado para aprovechar las capacidades nativas de los modelos Gemini de Google, particularmente sus grandes ventanas de contexto y razonamiento multimodal nativo.
A diferencia de los envoltorios genéricos, el «Motor de Agentes» de ADK está optimizado para mapear los pasos de razonamiento del agente directamente a las primitivas de Vertex AI. Esto permite un uso de tokens más eficiente y una latencia más baja.
Además, ADK proporciona mecanismos robustos para gestionar el estado y el contexto de la conversación. En flujos de trabajo complejos, mantener el historial de las salidas de las herramientas y los pasos de razonamiento intermedios es crucial para evitar que el agente «olvide» su objetivo original.
La Sinergia de ADK + LangChain: Lo Mejor de Dos Mundos
La decisión de emparejar ADK con LangChain representa una estrategia híbrida y pragmática. LangChain posee el ecosistema más grande de la industria de integraciones preconstruidas (Herramientas). En lugar de escribir código Python personalizado para cada interacción de API (Slack, Wikipedia, Jira), el sistema puede aprovechar las bibliotecas existentes de LangChain y envolverlas como herramientas compatibles con ADK.
El patrón de implementación común implica envolver una Tool o Chain de LangChain dentro de una FunctionTool de ADK. Esto permite que el agente ADK «empuñe» las capacidades de LangChain mientras mantiene la estructura arquitectónica robusta proporcionada por el marco de Google.
ADK actúa como el marco estructural del agente—el «Plano del Agente», que incluye la definición de objetivos, barandillas de seguridad y la lógica de orquestación primaria—mientras que LangChain actúa como el repositorio de utilidades tácticas.
3. La Capa de Gobernanza y Pasarela: LiteLLM
3.1 El Imperativo de la Independencia del Modelo
En el panorama de la IA que evoluciona rápidamente, atar una aplicación empresarial a un único proveedor de modelos (Vendor Lock-in) es un riesgo estratégico significativo. El rendimiento, el precio y la disponibilidad de los modelos fluctúan mensualmente. Un modelo que es el estado del arte hoy podría ser superado por un competidor mañana.
LiteLLM sirve como la capa de abstracción crítica—una Pasarela de Modelos (Model Gateway)—que se sitúa entre la lógica de la aplicación (Agentes ADK) y las API de modelos sin procesar.
3.2 Estandarización e Interoperabilidad Técnica
LiteLLM traduce los esquemas de API propietarios de varios proveedores (Vertex AI, Anthropic, Bedrock, Azure) en un formato estandarizado, típicamente el formato de API de OpenAI Chat Completion.
Al codificar los agentes ADK para interactuar con el proxy de LiteLLM en lugar de directamente con Vertex AI u OpenAI, el equipo de ingeniería puede cambiar los modelos subyacentes simplemente cambiando un archivo de configuración en el proxy de LiteLLM. No es necesario reescribir ningún código de aplicación.
4. La Capa de Infraestructura :Migración de Azure Kubernetes a GKE
4.1 Arquitectura de Tres Entornos Aislados
La transición desde Azure Kubernetes Service (AKS) hacia Google Kubernetes Engine (GKE) no fue un mero movimiento de «lift-and-shift», sino una reingeniería profunda motivada por la necesidad de crear entornos agénticos estrictamente aislados. Los sistemas de IA autónomos presentan riesgos únicos: pueden ejecutar código, consumir recursos de forma impredecible y requieren acceso granular a datos sensibles. Operar estos sistemas en un clúster monolítico compartido, como se hacía anteriormente en Azure, introducía riesgos inaceptables de seguridad y complejidad operativa.
Para resolver esto, se diseñó una topología basada en el despliegue tres clústeres físicos segregados, cada uno con un propósito y nivel de confianza específico, garantizando que cada entorno pueda desempeñar sus funciones agénticas sin interferencias ni riesgos cruzados.
4.2 Beneficios del Aislamiento Multi-Clúster
Esta estrategia de «divide y vencerás» aporta ventajas operativas críticas:
-
Contención de Riesgos: Si un agente experimental en el Clúster de Red Interna se desestabiliza o consume demasiada CPU, no afecta el rendimiento ni interrumpe el servicio a los clientes.
-
Políticas de Seguridad Granulares: El clúster de clientes puede tener restricciones distintas a las internas.
-
Ciclos de Vida Independientes: Permite actualizar, parchear o escalar cada entorno de forma independiente sin ventanas de mantenimiento globales.
5. Conclusión y Perspectiva Futura
La migración a un stack compuesto por MongoDB Atlas Vector Search, Google ADK, LiteLLM y GKE es un paso decisivo hacia la madurez en la implementación de la IA Generativa.
Esta arquitectura resuelve la deuda técnica inmediata del retraso de sincronización y la seguridad fragmentada, al tiempo que sienta las bases para la próxima generación de IA: los Sistemas Agénticos.
Escalabilidad Operativa Real
Ese futuro proyectado, sin embargo, ya se ha materializado. Los asistentes han completado su migración a esta nueva arquitectura en sus propios entornos, operando bajo estos nuevos estándares de robustez.
La prueba definitiva de esta flexibilidad es el despliegue de un asistente específico para GRC (Gobierno, Riesgo y Cumplimiento) en el clúster interno. Como se detalla en el análisis de VIA (Vitaly Intelligent Assistant).
Este caso de uso es crítico porque engloba herramientas totalmente diferentes para la búsqueda y recuperación (RAG) bajo el mismo paraguas arquitectónico. Esto pone de manifiesto una escalabilidad operativa real: el sistema no solo soporta más carga, sino que es capaz de orquestar flujos de trabajo y herramientas heterogéneas sin fricción.
Una respuesta a «Aitaly – Más allá del RAG: La Evolución hacia una Plataforma de Agentes Inteligentes»
[…] nuestra última entrada analizamos cómo Aitaly está evolucionando hacia una plataforma de agentes inteligentes. Hoy queremos aterrizar esa tecnología en una solución diseñada para eliminar uno de los mayores […]