La lectura de texto de un documento PDF puede llegar a ser una tarea complicada debido a que hay muchos factores involucrados que afectan a la posibilidad y/o precisión de la extracción de texto.
La librería que hace posible esta tarea es PDFBox (para acceder a la documentación de la librería hacer click aquí). El equipo de esta librería nos advierte de algunas comprobaciones que debemos de tener en cuenta antes de usar su herramienta de extracción de texto para que la lectura se haga de forma correcta:
- Abre el PDF en Acrobat e intenta copiar texto desde ahí. Si pegas la copia realizada en cualquier otro sitio que admite texto (por ejemplo Word) y resulta ser el mismo texto que copiaste, entonces PDFBox debería poder extraer dicho texto. En otras palabras, si Acrobat puede, PDFBox también.
- Puede que el archivo PDF sea una imagen en lugar de un texto. Podemos verificar este hecho de igual forma con Acrobat. Si no nos deja seleccionar texto, entonces es una imagen y no podremos extraer texto de ella.
PDFBox se vale de un recuadro cuya dimensiones debemos proporcionar para que se extraiga el texto en dicha área. Deberemos introducir las coordenadas de la esquina superior izquierda junto con la anchura y altura del mismo para delimitar el recuadro.
Existen varios métodos para determinar la región rectangular de la cual queremos extraer texto, pero en este post veremos únicamente el método “paint-based” paso a paso.
Antes de empezar, llamaremos coordenadas-java a las coordenadas de cualquier punto de nuestro PDF abierto en Java (veremos más sobre esto más adelante). Por otro lado, llamaremos coordenadas-pixel a las coordenadas de cualquier punto seleccionado con una herramienta en la aplicación “Paint”.
![]()
Imagen: Herramienta en Paint colocada sobre la coordenada-pixel (61,68).
Veamos ahora los pasos a seguir para llevar a cabo el método mencionado anteriormente:
- Calcular las dimensiones de nuestro pdf en java:

Nota: visto esto, aclaramos que la coordenada-java de la esquina superior izquierda de nuestro PDF es (0,0) mientras que la coordenada-java de la esquina inferior derecha es (d2,d1). - Hacer una captura de pantalla del PDF en cualquier visor de PDF.
- Pegar la captura de pantalla en la aplicación “Paint”.
- Seleccionar cualquier herramienta y colocarla en la esquina superior izquierda del PDF. Con esto tenemos las coordenadas-pixel de nuestro PDF, supongamos que son (a,b), que corresponden a la coordenada-java (0,0).
- Seleccionar cualquier herramienta y colocarla en la esquina inferior derecha del PDF. Con esto tenemos las coordenadas-pixel de nuestro PDF, supongamos que son (c,d), que corresponden a la coordenada-java (d2,d1).
- Seleccionar cualquier herramienta y colocarla en la esquina superior izquierda del rectángulo del cuál queremos extraer texto. Supongamos que estas coordenadas son (e,f).
- Seleccionar cualquier herramienta y colocarla en la esquina inferior derecha del rectángulo del cuál queremos extraer texto. Supongamos que estas coordenadas son (g,h).
- Ya tenemos las coordenadas-pixel del rectángulo del cual queremos extraer texto [(e,f), (g,h)]. El último paso consiste en transformarlas a coordenadas-java. Podemos seguir la siguiente fórmula:
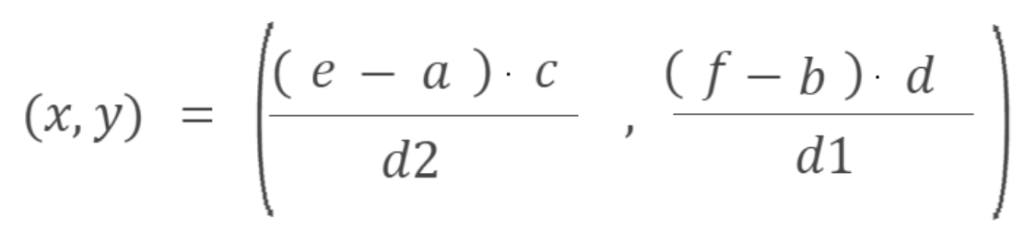
Con esta transformación hemos pasado las coordenadas-pixel (e,f) a las coordenadas-java (x,y). Para pasar las coordenadas-pixel (g,h) a coordenadas-java basta aplicar la misma fórmula pero sustituyendo e por g y f por h.
Pequeño ejemplo de aplicación de la extracción con las coordenadas que hemos visto:
